Olá @GuilhermeMunhoz!
Você deve estar enfrentando um problema de cache.
Na versão legado do Extrator de Arquivos, o cache ocorre do lado do servidor:
-
Antes de extrair o arquivo, o sistema verifica se ele já foi extraído anteriormente no servidor.
-
Se já foi extraído, ele usa o mesmo arquivo, caso contrário faz a extração e mantém o arquivo em um diretório no servidor.
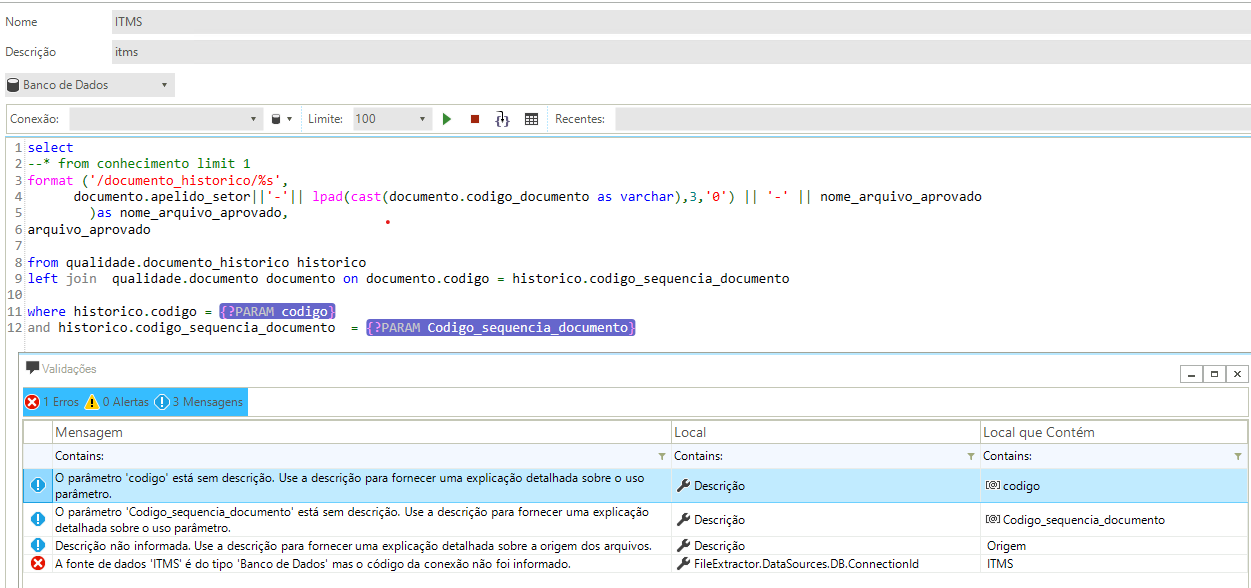
O arquivo extraído fica salvo em um caminho que termina com o nome do arquivo retornado no comando SQL. Na seu caso seria algo do tipo:
/documento_historico/apelidosetor-000-nomearquivo.ext
Se o registro for excluído do banco de dados, e um novo registro for incluído, resultando no mesmo nome de arquivo, o sistema continuará retornando o arquivo previamente extraído.
Para resolver essa situação com o Extrator de Arquivos antigo, basta adicionar uma informação única no caminho, como por exemplo: versão, hora do upload ou hash do arquivo.
Exemplos:
/documento_historico/v2/apelidosetor-000-nomearquivo.ext
/documento_historico/v3/apelidosetor-000-nomearquivo.ext
/documento_historico/202305231900/apelidosetor-000-nomearquivo.ext
Já no Extrator de Arquivos novo, o cache ocorre do lado do navegador. Neste caso, é o mecanismo de cache padrão do navegador entrando em ação, que armazena as resposta usando a URL como chave para isso.
Por exemplo, quando um arquivo for solicitado passando o parâmetro “codigo” com valor valor “1”, acontece uma requisição HTTP para o seguinte endereço:
api/fileextractors/<Codigo do Extrator>/downloadfile/?codigo=1
Neste caso, o navegador armazena o arquivo obtido em cache, e na próxima vez que a mesma URL for solicitada, a requisição não vai nem sequer chegar ao servidor.
Qualquer alteração na URL, romperia o cache. Por exemplo:
api/fileextractors/<Codigo do Extrator>/downloadfile/?codigo=2
api/fileextractors/<Codigo do Extrator>/downloadfile/?codigo=1&v=2
Neste caso, existem duas alternativa para solucionar o problema:
-
Criar um parâmetro no Extrator de Arquivos para passar um valor capaz de gerar uma URL diferente e romper o cache (ex. “v” de versão)
-
Desabilitar o cache, informando 0 no tempo de duração do mesmo. Essa é uma opção exclusiva do Extrator de Arquivos novo.
Quanto ao fato de não estar salvando a conexão informada no Extrator de Arquivos novo, isso acontece porque nenhum Código de Atualização (Cód. Atualização) foi informado no cadastro da conexão. Uma mensagem de crítica deve estar sendo exibida na validação do Extrator, antes de salvar, apontando este erro.
O Código de Atualização é um identificador universal da conexão (e de qualquer Objeto), usado para encontrar referências em outros ambientes, quando os objetos desenvolvidos são exportados e importados. Todos os novos objetos, desenvolvimentos ou convertidos após o lançamento do Bot de Mensagens usam este código como identificador da conexão. Neste caso, basta clicar no botão “Gen” ao lado do campo para gerar um novo código, e depois salvar a conexão.